
Level Up Your Escalation Game
In today’s fast-paced business world, customer expectations are at an all-time high. One unresolved issue can quickly spiral into a PR crisis, damaging your brand and impacting your bottom line. Understanding escalation management is no longer optional; it's essential for business survival.
The field has come a long way from basic hierarchical escalation chains to the complex, data-driven models used today. This shift reflects the increasing complexity of customer interactions and the demand for swift resolutions. A truly effective modern escalation approach seamlessly blends established frameworks with practical strategies. This empowers your team to navigate challenging situations, minimize disruptions, and ultimately, bolster customer relationships.
Several factors have fueled this evolution. These include the rise of digital communication channels like Slack, the growing interconnectedness of systems, and the increasing importance of data-driven decisions. Theories such as the “Service Recovery Paradox” suggest that a well-handled service failure can actually boost customer loyalty. This highlights the potential of effective escalation management to turn negative experiences into positive ones.
10 Best Practices for Effective Escalation Management
This article presents ten powerful escalation management best practices to help your team master any challenge. These practices range from defining clear escalation paths to fostering a culture of continuous improvement.
-
Establish Clear Escalation Paths: Document who handles what and when. This avoids confusion and delays.
-
Leverage Data for Proactive Intervention: Use data to identify potential issues before they escalate. Tools like Google Analytics can be invaluable here.
-
Empower Frontline Staff: Give them the authority to resolve common issues quickly, reducing escalation frequency.
-
Set Clear Service Level Agreements (SLAs): Define acceptable response and resolution times for each escalation level.
-
Communicate Effectively: Keep customers informed throughout the escalation process. Transparency builds trust.
-
Document Everything: Maintain detailed records of every escalated incident. This information provides valuable insights.
-
Foster a Culture of Accountability: Ensure everyone involved understands their role and responsibilities.
-
Use Escalations as Learning Opportunities: Analyze each incident to identify root causes and prevent future occurrences.
-
Regularly Review and Update Your Escalation Process: Keep your system adaptable to changing business needs.
-
Invest in Training: Equip your team with the skills and knowledge to handle escalations effectively.
By implementing these best practices, you can build a robust escalation management system. This will not only enable your team to handle any challenge effectively but also transform potential crises into opportunities for growth and improved customer satisfaction.
1. Tiered Escalation Framework
A cornerstone of effective escalation management is the Tiered Escalation Framework. This structured approach defines multiple levels of escalation based on the severity, impact, and urgency of issues. Think of it as organizing a relay race, where each runner (tier) handles a specific leg and knows exactly when and to whom to pass the baton. Each tier corresponds to different roles, responsibilities, and resolution timeframes, creating a clear path for efficient issue resolution.
A typical tiered framework involves levels like L1 (first-line support), L2 (technical specialists), and L3 (subject matter experts or management). Each level has specific response time objectives. L1 might have a 5-minute response time for acknowledging an issue, while L2 might target a 1-hour resolution for less complex problems. Documented handoff processes between tiers, including clear escalation criteria, are essential. An authority matrix clarifies decision-making capabilities at each level, empowering the right people to resolve issues effectively.
Features of a Tiered Escalation Framework
- Clearly Defined Escalation Levels: Typically L1, L2, L3, etc.
- Specific Response Time Objectives: For each tier.
- Documented Handoff Processes: Between tiers.
- Authority Matrix: Outlining decision-making capabilities at each level.
Benefits of Implementing a Tiered System
- Provides Clear Accountability and Ownership: Each tier has specific responsibilities.
- Ensures Appropriate Resource Allocation: Matching issue complexity with expertise.
- Prevents Unnecessary Escalation: Routine issues are handled at the appropriate level.
- Creates Predictable Resolution Paths: Provides stakeholders with transparency and confidence.
Potential Drawbacks
- Silo Creation: If poorly implemented, communication between tiers can suffer.
- Potential Delays: Inefficient handoffs can hinder resolution times.
- Rigidity: Overly strict adherence to the framework can be problematic in dynamic environments.
- Maintenance: Requires regular review and updates to remain effective.
Real-World Examples
- IBM's Global Technology Services: Implements a four-tier escalation model that has reduced resolution times.
- Salesforce: Connects severity levels to specific response time SLAs in their customer support.
- ServiceNow: Incorporates tiered escalation with automated routing within their incident management framework.
The concept of tiered escalation has been popularized by frameworks like ITIL and ISO/IEC 20000, along with industry practices like those of Cisco's Technical Assistance Center (TAC). These models have proven effective in streamlining issue resolution and improving customer satisfaction.
Tips for Successful Implementation
- Document Clear Criteria for Escalation: Define the triggers for moving between tiers.
- Train Team Members: Ensure everyone understands the escalation procedures.
- Regular Review: Analyze escalation data to identify bottlenecks and areas for improvement.
- Dual Escalation Paths: Include both technical and management escalation paths.
You might be interested in: Our guide on… various support topics.
By incorporating a well-designed Tiered Escalation Framework, organizations can significantly improve their issue resolution process. This leads to increased efficiency, improved customer satisfaction, and better resource utilization, making it a crucial element of any successful escalation management strategy.
2. RACI Matrix for Escalation Management
In the high-pressure environment of escalation management, clear roles are essential. A slow response or miscommunication can severely impact customer satisfaction, damage a company's reputation, and even lead to financial losses. This is where the RACI matrix becomes indispensable. RACI, an acronym for Responsible, Accountable, Consulted, and Informed, offers a structured way to define roles and responsibilities within an escalation process.
This clarity empowers teams to act quickly and decisively during critical incidents, securing its place as a best practice for escalation management.
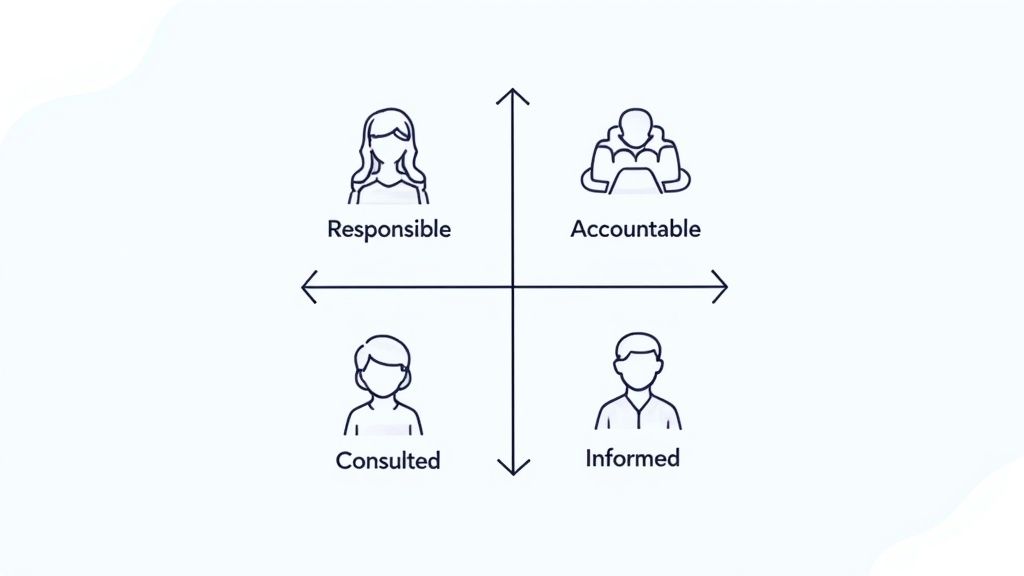
The matrix visually connects each escalation step with the individuals or teams involved, clearly outlining their level of participation. For each task, individuals are assigned one of the following roles:
- Responsible: The person who does the work to complete the task.
- Accountable: The person ultimately answerable for the task's accurate and complete execution. Only one person should be Accountable for each task.
- Consulted: Individuals who need to be consulted before a decision or action is taken. These are often subject matter experts or stakeholders with important insights.
- Informed: Individuals who need updates on progress or decisions, but who are not actively involved in the task.
Features and Benefits
The RACI matrix offers several key features:
- Clear Role Definitions: Eliminates confusion and uncertainty during critical incidents.
- Visual Format: Offers an easily accessible overview of roles and responsibilities.
- Process-Specific Assignments: Allows for customized RACI models based on different types of escalations (e.g., technical problems, customer complaints).
- Distinct Decision-Makers and Contributors: Clearly identifies those responsible for making decisions and those who contribute to implementation.
By using a RACI matrix, organizations can expect several benefits:
- Reduced Confusion: Teams know precisely who to contact and what actions to take.
- Faster Escalations: Streamlines responses, minimizing downtime and customer impact.
- No Duplicate Efforts: Ensures efficient resource use and eliminates redundant work.
- Full Stakeholder Involvement: Keeps everyone informed and encourages collaborative problem-solving.
Real-World Examples and Evolution
Major companies like Amazon Web Services (AWS) and Microsoft Azure use RACI matrices for incident management, leading to improvements in Mean Time To Resolution (MTTR). AWS reported a 35% MTTR improvement after implementing RACI. Accenture also utilizes RACI models for client escalation management. These examples demonstrate RACI's effectiveness in complex, high-pressure environments.
The RACI model, developed in the 1970s, has gained widespread use through organizations like the Project Management Institute (PMI) and the ITIL Service Operation framework. Its simplicity and effectiveness have made it a standard practice across various industries, particularly in IT and customer service.
Practical Tips for Implementation
- Create Separate Matrices: Develop distinct RACI matrices for different escalation types.
- Regular Reviews: Review and update the RACI model quarterly or as organizational changes occur.
- Documentation and Training: Integrate the RACI model into escalation documentation and training materials.
- Automation: Use automation tools to notify the right people based on RACI assignments.
Pros and Cons
While offering substantial benefits, the RACI matrix also has potential drawbacks:
Pros: Reduces confusion, speeds up escalations, eliminates duplicate efforts, ensures stakeholder engagement.
Cons: Can become outdated, may be complex for smaller organizations, requires upfront development effort, and is ineffective without proper introduction and training.
By considering these pros and cons and implementing the provided tips, organizations can effectively use the RACI matrix to optimize escalation management and ensure a quick, coordinated response to critical incidents.
3. Swarming Response Model
The Swarming Response Model represents a fundamental change in how we handle escalations. It moves away from the traditional tiered support structure and embraces a collaborative, simultaneous approach. Instead of passing an issue down a chain of command, swarming assembles a cross-functional team of experts who address the problem together, in real-time. This eliminates time-consuming handoffs and prevents knowledge loss, leading to faster resolutions and more comprehensive solutions.
This model is a must-have for any best practices list because it demonstrably reduces Mean Time To Resolution (MTTR) and improves customer satisfaction. It creates a dynamic, responsive environment where specialists engage directly with the issue, using their combined expertise to solve problems quickly. Key features of a swarming model include real-time collaboration across different areas of expertise, direct engagement of specialists, dynamic team formation based on the issue, and continuous knowledge sharing.
Real-World Examples of Swarming
Several well-known organizations have successfully implemented swarming models. Spotify's engineering teams, for instance, use swarming to address critical production issues and have seen a 40% reduction in resolution times. Atlassian also transitioned from tiered support to swarming for customer-impacting incidents, streamlining their response process. Red Hat adopted swarming for their premium support customers, resulting in significant improvements in customer satisfaction. These examples showcase the benefits of swarming across various industries and company sizes.
Advantages and Drawbacks of Swarming
The advantages of swarming are clear: reduced MTTR, elimination of knowledge loss, enhanced skill development through collaboration, and more holistic solutions. However, there are potential drawbacks. Swarming can be resource-intensive for less complex issues and requires strong facilitation to ensure effective teamwork. Its success also depends on the availability of specialists and can present challenges in tracking individual contributions.
Tips for Implementing a Swarming Model
For organizations considering a swarming model, these tips are crucial:
- Define clear criteria: Establish specific triggers for activating a swarm. Swarming is most effective for complex, high-impact issues.
- Establish a swarm facilitator role: This person coordinates the team, ensures clear communication, and keeps the team focused on efficient problem-solving.
- Document lessons learned: After each swarm, conduct a debriefing to identify areas for improvement and refine the process.
- Utilize collaboration tools: Invest in tools that support real-time information sharing, communication, and documentation, such as Slack or Microsoft Teams.
The swarming model, promoted by organizations like the Consortium for Service Innovation, the Knowledge-Centered Service (KCS) methodology, and the DevOps movement, is a powerful approach to escalation management. By encouraging collaboration and empowering expert teams, organizations can significantly improve response times, solution quality, and customer satisfaction.
4. Service Level Agreement (SLA) Driven Escalation
Service Level Agreements (SLAs) are a powerful tool for ensuring timely issue resolution. They use predefined timeframes to automatically escalate unresolved issues to higher support tiers or management. This prevents issues from stagnating and ensures appropriate resources are allocated to complex or time-sensitive problems.
This method adds accountability and predictability. Clear expectations for response and resolution times are set for customers, support agents, and management. Automated notifications keep everyone informed of progress and escalation actions.
Different Levels for Different Needs
Differential SLAs, based on issue priority and business impact, allow you to prioritize critical issues. A "Severity 1" outage might have a much shorter SLA than a minor bug report. This ensures urgent issues are addressed quickly.
The benefits of SLA-driven escalation are numerous. It prevents neglect, creates predictable expectations, enables proactive management, and provides metrics for process improvement. Imagine a critical bug impacting a customer's ability to use your software. With SLA-driven escalation, the system automatically escalates the issue and notifies managers if it isn't resolved within a specific timeframe, perhaps two hours. This minimizes the impact on the customer.
Potential Drawbacks to Consider
However, this approach has drawbacks. Improperly set SLAs (too aggressive or too lenient) can create artificial pressure, impacting quality. It can also trigger unnecessary escalations, burdening higher support tiers. A rigid focus on SLA timelines can overshadow actual progress. Implementing effective SLA-driven escalation requires sophisticated tracking systems like Zendesk.
Real-World Examples of SLA Success
Real-world examples demonstrate its effectiveness. Zendesk’s customer service platform leverages SLA-driven escalation, helping companies reduce backlogs. Oracle Cloud Infrastructure operations teams utilize it for infrastructure incidents, minimizing downtime. PagerDuty incorporates SLA-based escalation paths, ensuring the right people are alerted.
SLA-driven escalation gained popularity alongside IT Service Management (ITSM) frameworks like ITIL (Information Technology Infrastructure Library) and standards from HDI (Help Desk Institute) and Gartner. ITIL Service Level Management emphasizes defining, monitoring, and managing SLAs.
Practical Tips for Implementation
To implement SLA-driven escalation effectively:
- Regularly review and adjust SLAs: Analyze data to ensure SLAs are realistic and aligned with capabilities and expectations.
- Include business hours considerations: Factor in business hours and holidays to avoid unnecessary after-hours escalations.
- Implement 'warning' notifications: Send warnings before an SLA breach, allowing proactive issue addressal.
- Balance SLA-driven escalation with quality metrics: Monitor resolution quality and customer satisfaction alongside SLA timelines.
SLA-driven escalation is a best practice for introducing structure, accountability, and predictability. Automating escalation based on predefined timeframes ensures timely attention for critical issues, improves customer satisfaction, and optimizes resource allocation. Careful planning and implementation are crucial, but the benefits can significantly enhance your escalation management strategy.
5. Customer-Centric Escalation Paths

Traditional escalation paths can be a nightmare for customers. They often resemble confusing mazes, leading to frustration and a feeling of being ignored. A customer-centric approach changes this by designing the escalation process from the customer's point of view. This prioritizes transparency, giving customers more control and making it easier to get the support they need.
This customer-focused approach aims to simplify the escalation process, minimizing the effort required from the customer. Some key features include:
- Multiple communication channels: Offering a variety of contact options like phone, email, live chat, or social media lets customers choose their preferred method.
- Easy-to-understand language: Avoid technical jargon and internal terminology. Instead, use clear, empathetic language that reassures the customer you're taking their issue seriously.
- Real-time status updates: Keep customers informed about the progress of their case. This reduces anxiety and builds trust.
- Empowered front-line staff: Give representatives the authority to escalate issues without needing managerial approval, speeding up the resolution process.
Why This Approach Works
Customer expectations are higher than ever, and online reviews and social media have a huge impact. This has driven the shift toward customer-centric escalation management. Concepts like Amazon's customer obsession principle, championed by Jeff Bezos, and the focus on reducing customer effort, highlighted in The Effortless Experience by Matthew Dixon, have been instrumental in this change. The Net Promoter System also emphasizes the importance of addressing customer pain points to improve loyalty.
Real-World Examples
Several companies have seen significant success with customer-centric escalation management:
- Zappos: Famous for its outstanding customer service, Zappos empowers its representatives to escalate issues without needing a manager's approval, contributing to its exceptional customer experience.
- American Express: By implementing a customer-centric escalation model, American Express reportedly reduced second contacts by 25%. This demonstrates improved first-contact resolution rates and higher customer satisfaction.
- T-Mobile: Their "Team of Experts" model replaced traditional escalation tiers with dedicated resolution teams. This has led to significant improvements in customer satisfaction and loyalty.
Pros and Cons
Like any strategy, there are advantages and disadvantages to consider:
| Pros | Cons |
|---|---|
| Improved customer satisfaction | Potential for escalation inflation |
| Reduced customer effort | May create expectation of immediate resolution |
| Fewer social media/executive escalations | Requires significant staff training |
| Valuable voice-of-customer data | Balancing empowerment and operational efficiency |
Implementation Tips
Here are a few tips for implementing a customer-centric escalation process:
- Use customer-focused language: Speak clearly and empathetically, avoiding technical jargon.
- Set clear expectations: Create escalation 'guarantees,' like, "We'll respond to your escalated issue within 24 hours."
- Confirm resolution: Follow up with customers to ensure their issue is resolved and they are satisfied.
- Train staff to recognize emotional cues: Equip your team to identify and address situations where a customer is becoming frustrated.
By adopting a customer-centric approach to escalation management, businesses can transform a potential negative experience into a positive one, strengthening customer relationships and increasing loyalty.
6. Major Incident Management Protocol
A major incident is any event that significantly disrupts business operations. This disruption can impact customers, revenue, or reputation. When these critical situations occur, a well-defined Major Incident Management Protocol is essential. This protocol helps navigate the chaos and restore normal operations quickly.
This specialized escalation framework provides structure, clarity, and coordinated action. This is especially crucial when time is of the essence. The protocol isn't simply about fixing the immediate problem. It's about managing the entire incident lifecycle. This includes initial detection, response, resolution, and the post-incident review.
The protocol encompasses predefined roles and clear communication channels. It also includes war room procedures and executive communication protocols. The core idea is to equip your organization with a pre-determined playbook. This avoids ad-hoc, reactive scrambling during high-pressure situations.
Key Features of a Robust Protocol
- Designated Incident Commander: A single point of authority empowers rapid decisions and resource mobilization. This avoids confusion and ensures accountability.
- Pre-established Communication Channels and Tools: Defining communication pathways (e.g., conference bridges, dedicated Slack channels) keeps everyone aligned and informed.
- Regular Situation Updates with Standardized Formats: Consistent and concise updates keep stakeholders informed on incident status, progress, and expected resolution.
- Post-Incident Review Requirements and Templates: Structured post-mortems help identify root causes, improve processes, and prevent future incidents. This fosters a culture of learning.
Why This Matters
A Major Incident Management Protocol is a key part of any escalation management best practices. It brings order to chaotic situations. By providing a clear structure, the protocol ensures a swift mobilization of resources, and creates consistent executive visibility. Ultimately, it minimizes the impact of major disruptions.
Pros and Cons
Let's take a look at the advantages and disadvantages of implementing a Major Incident Management Protocol:
| Pros | Cons |
|---|---|
| Provides structure during chaotic events | Can be over-engineered for smaller organizations |
| Ensures quick resource mobilization | Requires regular drills and training |
| Creates consistent executive visibility | May prioritize process over flexibility |
| Facilitates learning and prevention | Often requires significant documentation |
Real-World Examples
Several major companies utilize robust incident management protocols:
- Google's Site Reliability Engineering (SRE) teams: Google's SRE practices emphasize incident management and have reportedly reduced Mean Time To Resolution (MTTR) for major outages by 50%. Their approach provides a strong example of a well-structured protocol improving incident response.
- Netflix: Netflix uses clearly defined roles and responsibilities in their incident response process. This has helped them manage significant global streaming outages efficiently.
- Financial Institutions (e.g., JPMorgan Chase): These institutions use rigorous major incident protocols to address critical security and operational crises. This demonstrates the protocol's broad applicability.
Evolution and Popularization
Formalized incident management gained traction through the rise of SRE practices at Google and the ITIL (Information Technology Infrastructure Library) framework. Models like the National Incident Management System (NIMS) have also shaped the development and adoption of standardized incident response.
Practical Implementation Tips
Here are a few practical tips for implementing a Major Incident Management Protocol:
- Regular Simulations: Conduct “fire drills” to practice procedures and identify weaknesses.
- Role Cards: Create concise role cards outlining responsibilities for each incident function (e.g., Incident Commander, Communications Lead).
- Communication Templates: Develop pre-approved communication templates for various stakeholders to ensure consistent messaging.
- Blameless Post-Mortems: Foster a culture of learning from incidents without assigning blame. This encourages open communication and systemic issue identification.
By incorporating a Major Incident Management Protocol into your escalation strategy, you empower your teams to handle critical situations effectively. This minimizes disruption and protects your business from the consequences of major incidents.
7. Data-Driven Escalation Criteria
Moving beyond gut feelings and subjective assessments, data-driven escalation criteria offer a modern and objective approach to escalation management. This method uses quantifiable metrics and predefined thresholds to trigger escalations, ensuring consistency, reducing unnecessary escalations, and promoting a more proactive approach to issue resolution. Instead of relying on individual judgment, data-driven escalation uses objective data to determine when an issue needs a higher level of attention. This makes it a cornerstone of efficient and scalable escalation management.
How It Works
Data-driven escalation criteria involve establishing specific, measurable metrics that correspond to different escalation levels. These could include metrics like customer wait times, error rates, website downtime, or the number of open support tickets.
Automated monitoring systems constantly track these metrics. When a predefined threshold is crossed, the system automatically triggers the appropriate escalation, notifying the designated team or individual. This removes guesswork and ensures a consistent response to similar issues.
Furthermore, multivariate triggers, which consider multiple factors simultaneously, can provide a more nuanced and accurate escalation response.
Features and Benefits
- Clearly defined quantitative thresholds: This removes ambiguity and ensures consistent escalation procedures.
- Automated monitoring and alert systems: This enables proactive identification of issues requiring escalation.
- Multivariate triggers: This allows for more sophisticated escalation logic based on the interplay of multiple factors.
- Regular refinement based on outcome analysis: This continuously improves the accuracy and effectiveness of the escalation criteria.
These features translate into tangible benefits:
- Reduces subjective decision-making: Eliminates biases and promotes fairness in escalation processes.
- Creates consistent treatment across similar issues: Ensures all customers and issues receive appropriate and timely attention.
- Enables predictive escalation: By identifying trends and patterns, data-driven escalation can predict potential problems before they become critical.
- Provides clear justification for escalation decisions: Data provides an objective rationale for each escalation, enhancing transparency and accountability.
Pros and Cons
Pros: The benefits include reduced subjectivity, consistent treatment, predictive capabilities, and clear justification for escalations.
Cons:
- May miss nuanced situations: Highly structured metrics may not capture every unique circumstance.
- Requires sophisticated monitoring and analytics capabilities: Implementing and maintaining these systems requires technical expertise and resources. Tools like Datadog and Splunk can help manage this complexity.
- Can lead to alert fatigue: Poorly defined thresholds can result in excessive notifications, desensitizing teams to genuine alerts.
- Needs regular calibration: Ongoing monitoring and adjustment are necessary to ensure the effectiveness of the criteria.
Real-World Examples
- Datadog: Implemented data-driven incident escalation, reportedly reducing false positives by 35% and improving response times.
- Adobe: Uses algorithmic approaches within its cloud services to determine when to escalate infrastructure issues, ensuring optimal performance and minimizing downtime.
- Capital One: Leverages machine learning in its fraud detection systems to determine the appropriate escalation paths for suspicious transactions.
Tips for Implementation
- Start small and scale: Begin with a few key metrics and gradually expand the system as your understanding and capabilities mature.
- Balanced scorecard: Use a combination of indicators rather than relying on a single trigger to avoid skewed results.
- Feedback loop: Implement a system to track escalation outcomes and use this data to refine your criteria.
- Human validation: For high-impact escalations, combine automated triggers with human validation to prevent unintended consequences.
Evolution and Popularization
Data-driven escalation has gained significant traction due to the rise of the AIOps movement, platforms like Splunk's IT Service Intelligence, and the adoption of Site Reliability Engineering (SRE) practices. These methodologies emphasize automation, data analysis, and continuous improvement, all of which are core tenets of data-driven escalation. By embracing these principles, organizations can move beyond reactive escalation management and build a proactive system that anticipates and addresses issues before they impact customers or business operations.
8. Escalation Prevention Through Proactive Intervention
Escalation prevention through proactive intervention is a significant change in how we approach customer service. It’s about moving away from simply reacting to problems and instead, anticipating and resolving them before they even impact the customer. This focus on prevention is why it's a customer service best practice, addressing the root causes of escalations and improving both customer satisfaction and operational efficiency.
This proactive approach relies on several key elements:
-
Predictive Analytics: This involves analyzing data like customer behavior, product usage, and support tickets to spot patterns and trends that might indicate future issues.
-
Proactive Outreach: Reaching out to customers who seem to be at risk before they run into a problem. Imagine proactively contacting a customer who's struggling with a new feature or giving someone a heads-up about a potential service disruption.
-
Regular Health Checks and Monitoring: Constant monitoring of systems, services, and customer interactions can reveal potential issues in real-time. This could include things like tracking website performance, application uptime, or even social media sentiment.
-
Early Intervention Authority for Front-Line Teams: Giving front-line teams the power to address potential issues immediately, without needing managerial approval. This speeds up resolutions and prevents problems from escalating.
Benefits of Proactive Intervention
Proactive intervention offers a multitude of benefits:
Pros:
- Reduces Overall Escalation Volume: Catching issues early stops them from becoming full-blown escalations.
- Improves Customer Experience: Preventing problems creates a smoother, more positive experience for your customers.
- Lowers Cost of Resolution: Resolving issues early is generally much cheaper than dealing with escalated problems.
- Shifts Organizational Focus from Reactive to Proactive: Cultivates a more proactive, forward-thinking culture within your company.
Challenges of Proactive Intervention
Of course, there are challenges to consider as well:
Cons:
- Requires Significant Investment in Monitoring and Analytics: You’ll need resources and expertise to set up the infrastructure for data analysis and prediction.
- May Result in Addressing Issues that Would Resolve Naturally: Sometimes, potential problems resolve themselves, meaning you might spend effort on issues that wouldn't have escalated.
- Can be Difficult to Demonstrate ROI Since Prevented Escalations are Invisible: Measuring success involves tracking "prevented escalations," which can be hard to quantify.
- Needs Cultural Shift from Traditional Reactive Approaches: Transitioning from a reactive to a proactive mindset requires organizational change.
Real-World Examples of Proactive Intervention
The roots of proactive intervention lie in concepts like Total Quality Management, and it’s gained traction with the growth of the Predictive Customer Service model and Digital Experience Monitoring practices. Here are a few real-world success stories:
- Microsoft’s Xbox Live team: By using predictive intervention based on player behavior, Microsoft reduced formal escalations by 28%.
- American Airlines: They use proactive notifications and resolution for potential travel disruptions like flight delays or cancellations, minimizing customer frustration.
- Shopify’s merchant success team: Shopify proactively identifies online stores struggling with issues like low conversion rates or abandoned carts, intervening before merchants even contact support.
Tips for Implementing Proactive Intervention
Here’s how to successfully implement proactive intervention in your business:
- Develop leading indicators for common escalation types: Figure out the specific metrics that predict potential escalations.
- Implement "early warning systems" that alert appropriate teams: Set up automated alerts based on those leading indicators.
- Create dedicated proactive intervention teams with clear authority: Empower these teams to make quick decisions.
- Track "prevented escalations" as a key performance metric: Find ways to measure and demonstrate the impact of your efforts.
By addressing potential problems proactively, businesses can significantly improve the customer experience, cut operational costs, and create a more efficient and proactive support organization.
9. Executive Sponsorship Model
The Executive Sponsorship Model is a powerful approach to escalation management. It connects important issues directly with senior leaders, assigning specific executives to oversee major accounts, critical incidents, or strategic initiatives. This creates a clear pathway to upper management for quicker resolutions.
This high-level involvement ensures visibility and dedicated resources for critical matters. It also demonstrates a strong organizational commitment to customer success and effective problem-solving. This model becomes a valuable asset for businesses focused on providing excellent customer experiences and nurturing important relationships.
How It Works
This model assigns executive sponsors, typically C-level or VP-level, to specific areas. These could include:
- Key Accounts: Assigning an executive sponsor to a high-value client prioritizes their needs and ensures any major obstacles are quickly addressed.
- Critical Issues: When complex or high-impact problems occur, the executive sponsor can facilitate resolution using their authority and influence.
- Strategic Initiatives: Executive sponsorship offers leadership and resources to propel key projects forward and conquer challenges.
The model relies on direct escalation channels to these senior leaders, often bypassing multiple management layers. Regular reviews of escalated issues by executives ensure continued attention and accountability. Clear guidelines define when executive sponsors are needed, preventing overuse and protecting the integrity of standard procedures.
Benefits and Drawbacks
Pros:
- Demonstrates Commitment: Executive involvement clearly signals a dedication to resolving issues and keeping key stakeholders happy.
- Decision-Making Authority: Sponsors have the power to make quick, critical decisions, speeding up resolution.
- Accountability: Assigning senior leaders responsibility fosters accountability at the highest organizational levels.
- Stronger Relationships: Direct interaction with executives builds stronger relationships with key clients and partners.
Cons:
- Potential Bottlenecks: Over-reliance on executive sponsors can create bottlenecks if their workload becomes excessive.
- Undermining Standard Processes: Using executive escalation too often can weaken established processes and reduce the power of frontline teams.
- Dependency on Individuals: The model's effectiveness can depend heavily on the individuals acting as sponsors, making long-term sustainability a challenge.
- Costly Resource: Executive time is valuable and limited, making this model a potentially expensive solution.
Real-World Examples
- Salesforce: Known for its customer-focused approach, Salesforce connects higher retention rates (reportedly as high as 40%) among enterprise accounts to its executive sponsorship program. This highlights the positive impact of high-level engagement on customer loyalty.
- SAP: SAP, under Bill McDermott's leadership, implemented a customer-first approach incorporating executive escalation for strategic clients. This C-level involvement ensured excellent service and responsiveness for key accounts.
- Cisco Systems: Cisco uses executive sponsorship to address major service disruptions and critical issues affecting important clients. This minimizes downtime and showcases their commitment to reliable service.
Tips for Implementation
- Define Clear Criteria: Establish specific triggers for executive sponsorship to prevent overuse and ensure appropriate use.
- Briefing Templates: Use standardized briefing templates to efficiently prepare executives for involvement, supplying them with essential context.
- Rotation of Assignments: Rotate assignments regularly to prevent burnout and balance the workload.
- Establish Clear Expectations: Outline clear expectations for executive engagement without diminishing the authority of other teams.
Evolution and Popularity
The Executive Sponsorship Model has gained popularity because of its success in enterprise account management and customer-centric strategies, such as those used by Bill McDermott at SAP and Marc Benioff at Salesforce (and his V2MOM system). Their focus on customer success and quick responses has highlighted the importance of direct executive involvement in critical situations. The Executive Sponsorship Model, by offering a clear path to senior leadership and demonstrating a strong commitment to resolution, has become a key tool for managing escalations and nurturing valuable relationships.
10. Post-Escalation Learning System
A robust escalation management process doesn't end when the immediate issue is resolved. Best practice involves learning from every significant escalation to prevent similar situations from recurring. This is where a Post-Escalation Learning System comes in. This continuous improvement approach treats each escalation as a valuable learning opportunity, implementing structured review processes, root cause analysis, and knowledge management to systematically improve escalation handling. This proactive strategy shifts the focus from reactive firefighting to proactive prevention, leading to better customer experiences and more efficient operations.
Features of a Post-Escalation Learning System
-
Mandatory post-escalation reviews for significant issues: This ensures that critical escalations aren't simply resolved and forgotten, but are thoroughly examined.
-
Root cause analysis methodology: Instead of just addressing surface-level symptoms, this delves into the underlying causes of the escalation. This leads to more effective, long-term solutions.
-
Knowledge base integration for lessons learned: Capturing and sharing insights from each escalation builds a valuable repository of knowledge accessible to the entire team. Consider tools like Confluence for this purpose.
-
Metrics tracking for escalation patterns and trends: Monitoring escalation data reveals recurring problems and informs strategic improvements.
Pros of a Post-Escalation Learning System
-
Creates organizational learning: Each escalation becomes a teaching moment, fostering a culture of continuous improvement.
-
Systematically reduces repeat escalations: By addressing root causes, the system prevents the same issues from arising repeatedly.
-
Identifies process improvements beyond individual incidents: Escalations often expose broader process flaws, leading to systemic enhancements.
-
Builds a knowledge foundation for training and onboarding: Lessons learned can be incorporated into training materials, accelerating the development of new team members.
Cons of a Post-Escalation Learning System
-
Requires discipline to maintain when teams are busy: Taking the time for thorough reviews can be challenging when workloads are high.
-
May be perceived as blame-oriented if not properly implemented: It's crucial to foster a blameless culture focused on learning and improvement, not on assigning fault.
-
Benefits are often long-term rather than immediate: The full impact of this system unfolds over time as improvements accumulate.
-
Requires significant knowledge management infrastructure: Effective knowledge capture and sharing requires appropriate tools and systems.
Real-World Examples
-
Toyota's application of Kaizen principles: Toyota's renowned Kaizen philosophy emphasizes continuous improvement, extending to their customer escalation management. They meticulously analyze escalations to identify areas for refinement.
-
Atlassian's post-incident review process: Atlassian reported a 32% reduction in repeat incidents after implementing a structured post-incident review process. This demonstrates the tangible benefits of a dedicated learning system.
-
Intel's Corrective Action Preventive Action (CAPA) system: Intel utilizes CAPA for customer escalations, ensuring that corrective actions are implemented and preventive measures are put in place.
Tips for Implementation
-
Implement a blameless review culture: Focus on systemic improvement, not individual blame.
-
Create templates for different types of post-escalation reviews: This streamlines the process and ensures consistency.
-
Track and measure the effectiveness of implemented changes: Monitor key metrics to assess the impact of improvements.
-
Schedule regular trend analysis sessions to identify patterns across multiple escalations: Look for recurring themes to identify broader areas for improvement.
Historical Context and Popularization
The concept of learning from mistakes and continuously improving processes is rooted in the work of W. Edwards Deming and his continuous improvement philosophy. The Knowledge-Centered Service (KCS) methodology further emphasizes knowledge sharing and learning within a service context. Peter Senge's concept of the "Learning Organization" provides a broader framework for creating organizations that learn and adapt.
This Post-Escalation Learning System deserves its place in this list because it transforms escalation management from a reactive process to a proactive driver of continuous improvement. By systematically learning from every significant escalation, organizations can reduce repeat issues, improve customer satisfaction, and create a more efficient support operation. This is a key differentiator between organizations that simply manage escalations and those that truly learn from them.
10-Point Escalation Management Best Practices Comparison
| Best Practice | 🔄 Implementation Complexity | ⚡ Resource Requirements | 📊 Expected Outcomes | ⭐ Key Advantages |
|---|---|---|---|---|
| Tiered Escalation Framework | Medium – defined levels with set handoff processes | Moderate – requires documentation and training | Predictable resolution and clear accountability | Structured escalation levels and defined handoffs |
| RACI Matrix for Escalation Management | High – significant upfront work and regular updates | Moderate – involves ongoing role clarity efforts | Eliminates confusion and reduces delays in high-pressure situations | Clear role definitions and stakeholder involvement |
| Swarming Response Model | High – demands real-time, cross-functional coordination | High – needs specialist availability and facilitation | Accelerated resolution with reduced MTTR | Holistic problem-solving and minimized handoffs |
| SLA Driven Escalation | Medium – relies on predefined time-based triggers | High – requires sophisticated tracking and alert systems | Timely escalations and improved process measurement | Predictable escalation with clear performance metrics |
| Customer-Centric Escalation Paths | Medium – tailored for customer ease but training needed | Medium – investment in customer-facing staff training | Enhanced customer satisfaction and transparent processes | Empowerment through transparency and simplified escalation |
| Major Incident Management Protocol | High – complex coordination and structured procedures | High – dedicated roles and communication tools required | Rapid, coordinated crisis response with executive visibility | Clear crisis structure and solid executive engagement |
| Data-Driven Escalation Criteria | High – integration of automation and analytics | High – investment in monitoring platforms and algorithms | Consistent, predictive escalation triggers | Objective, data-backed decision making |
| Escalation Prevention Through Proactive Intervention | High – requires predictive analytics and early warning systems | High – dedicated tools and proactive intervention teams | Reduced escalation volume and lower resolution costs | Early intervention and preemptive issue resolution |
| Executive Sponsorship Model | Medium – coordination with senior leadership | Medium – relies on executive time and focused engagement | Increased customer confidence and improved retention | High-level commitment and clear accountability |
| Post-Escalation Learning System | Medium – ongoing structured reviews and analysis | Medium – continuous knowledge management infrastructure | Continuous improvement and reduction of repeat issues | Organizational learning and process enhancement |
Ready to Implement These 10 Escalation Best Practices?
By implementing these ten escalation management best practices, organizations can significantly improve their issue resolution process. From establishing a tiered framework and defining clear RACI roles to using data-driven criteria and fostering a post-escalation learning system, these strategies lead to more efficient processes, happier customers, and a more resilient business.
Key principles to remember include prioritizing customer needs, empowering agents, establishing clear communication channels, and ensuring accountability at every level.
Assessing Your Current Process
Applying these concepts requires a thoughtful and structured approach. Start by assessing your current escalation process. Identify existing pain points and select the practices that best address your specific challenges.
For example:
- If unclear responsibilities are a frequent issue, implementing a RACI matrix is crucial.
- If slow response times are a problem, explore the swarming response model or SLA-driven escalation.
Begin with small, manageable steps. Pilot new practices in specific teams or for specific issue types before rolling them out company-wide.
Learning and Adapting for Long-Term Success
Learning and adaptation are essential for long-term success. Regularly review and refine your escalation strategies to adapt to evolving business needs and maintain optimal performance.
- Analyze escalation data to identify trends, pinpoint bottlenecks, and uncover areas for improvement.
- Solicit feedback from your support team to gain valuable insights into the effectiveness of implemented practices and identify any unforeseen challenges.
Staying Ahead of the Curve
The customer service landscape is constantly evolving. Ongoing trends, such as AI-powered support, personalized customer journeys, and proactive support, are shaping the future of escalation management. Stay informed about these developments and explore how they can be integrated into your strategies to enhance efficiency and customer satisfaction.
Key Takeaways
- Prioritize customer needs: Place the customer at the center of your escalation process.
- Empower your agents: Provide them with the tools and authority to resolve issues effectively.
- Establish clear communication: Ensure seamless information flow between all stakeholders.
- Data-driven decisions: Use data to inform escalation criteria and identify areas for improvement.
- Continuous improvement: Regularly review and refine your strategies for optimal performance.
Take Your Escalation Management to the Next Level
Ready to transform your customer service experience? SupportMan is a comprehensive tool designed to enhance customer satisfaction by integrating Intercom ratings directly into Slack. With instant notifications about customer feedback, your team can promptly address negative experiences and gather real-time insights to improve support strategies.
SupportMan empowers agents by facilitating discussions on ratings and metrics within Slack, fostering a culture of continuous improvement. Plus, save valuable time with automated weekly metrics reports, eliminating the need for constant Intercom dashboard checks. Bridge the communication gap between support and other departments, showcasing the impact of your team’s work on customer happiness. Start your hassle-free, no-credit-card-required free trial today and experience the power of real-time feedback.
